Using the barcoded forms service
in processes, you can extract barcode data from scanned images (TIF
or PDF files), convert the data to XML format, and use it in the
processes.
This Quick Start is most useful if you are already familiar with
the barcoded forms service. For more information about this service,
see
Services Reference for AEM forms
.
For example, a university’s business process uses a barcoded
form that students use to change either their name or their status
for the school records. Two barcodes on the form capture the information
that students enter on the form:
-
One barcode captures information from a drop-down menu
that the student uses to indicate whether they are changing their
name or their status.
-
The other barcode captures the details about their name or
status change.
The barcoded forms service is used to read the barcode and process
the information that it contains.
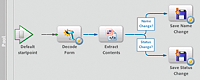
The following illustration shows the process diagram that is
used to read the barcode and process the data. The data is processed
differently depending on whether the student is changing their name
or their status. The routes that follow the Extract Content operation
have conditions that determine how to process the data accordingly.
The Decode Form operation reads the barcodes and saves the data
as XML. The data includes metadata about the barcodes as well as
the form data. The form data is in delimited-text format contained
in
content
elements.
The following XML is an example of the output that the Decode
Form operation produces. The data from each barcode is contained
in separate
barcode
elements:
-
The
barcode
element with the
id
attribute
value of
1
represents the barcode that contains
the details about the name or status change.
-
The
barcode
element with the
id
attribute
value of
2
represents the barcode that contains
the value of the drop-down menu that indicates whether a name or
status change has been submitted.
<?xml version="1.0" encoding="UTF-8"?>
<xb:scanned_image
xmlns:xb="http://decoder.barcodedforms.adobe.com/xmlbeans"
path="tiff" version="1.0">
<xb:decode>
<xb:date>2007-07-25T11:48:22.639-04:00</xb:date>
<xb:host_name>Win2K3-LC8</xb:host_name>
<xb:status type="success">
<xb:message/>
</xb:status>
</xb:decode>
<xb:barcode id="1">
<xb:header symbology="pdf417">
<xb:location page_no="1">
<xb:coordinates>
<xb:point x="0.119526625" y="0.60945123"/>
<xb:point x="0.44457594" y="0.60945123"/>
<xb:point x="0.44457594" y="0.78445125"/>
<xb:point x="0.119526625" y="0.78445125"/>
</xb:coordinates>
</xb:location>
</xb:header>
<xb:body>
<xb:content encoding="utf-8">t_SID t_FirstName t_MiddleName
t_LastName t_nFirstName t_nMiddleName
t_nLastName 90210 Patti Y Penne
Patti P Prosciutto
</xb:content>
</xb:body>
</xb:barcode>
<xb:barcode id="2">
<xb:header symbology="pdf417">
<xb:location page_no="1">
<xb:coordinates>
<xb:point x="0.119526625" y="0.825"/>
<xb:point x="0.44457594" y="0.825"/>
<xb:point x="0.44457594" y="0.9167683"/>
<xb:point x="0.119526625" y="0.9167683"/>
</xb:coordinates>
</xb:location>
</xb:header>
<xb:body>
<xb:content encoding="utf-8">t_FormType t_FormVersion
ChangeName 20061128
</xb:content>
</xb:body>
</xb:barcode>
</xb:scanned_image>
Because the form data is delimited text, it is difficult to parse
and extract information. Therefore, the Extract Content operation
is used to parse and save the data in XML format. In XML format,
XPath expressions can be used to access specific items of data.
The following XML is an example of the output that the Extract
Content operation produces for the first barcode on the form (
id
=
1
).
<?xml version="1.0" encoding="UTF-8"?>
<xdp:xdp xmlns:xdp="http://ns.adobe.com/xdp/"
xmlns:xfa="http://www.xfa.org/schema/xfa-data/1.0/">
<xfa:datasets>
<xfa:data>
<form1>
<t_SID>90210</t_SID>
<t_FirstName>Patti</t_FirstName>
<t_MiddleName>Y</t_MiddleName>
<t_LastName>Penne</t_LastName>
<t_nFirstName>Patti</t_nFirstName>
<t_nMiddleName>P</t_nMiddleName>
<t_nLastName>Prosciutto</t_nLastName>
</form1>
</xfa:data>
</xfa:datasets>
</xdp:xdp>
The following XML is an example of the output that the Extract
Content operation produces for the second barcode on the form (
id
=
2
).
<?xml version="1.0" encoding="UTF-8"?>
<xdp:xdp xmlns:xdp="http://ns.adobe.com/xdp/"
xmlns:xfa="http://www.xfa.org/schema/xfa-data/1.0/">
<xfa:datasets>
<xfa:data>
<form1>
<t_FormType>ChangeName</t_FormType>
<t_FormVersion>20061128 </t_FormVersion>
</form1>
</xfa:data>
</xfa:datasets>
</xdp:xdp>
The routes that follow the Extract Content operation include
conditions that determine the next operation to execute. The conditions
use the content of the
t_FormType
element from
the second barcode to determine which route is valid. The content
of this element represents the option that the student selected on
the form for changing their name or their status. Because the data
is in XML format, the content can be retrieved using XPath expressions.
For example, the following XPath expression retrieves the content
of the
t_FormType
element:
/process_data/contentList[2]/xdp:xdp/xfa:datasets/xfa:data/form1/t_FormType
 contentList
contentList
is a
list
variable that contains XML data. In this example, the variable stores the output of the Extract Content operation.