FrameMaker で、インデックスの並べ替え順序、文や文字による並べ替え、日本語の並べ替え順序を指定する方法について学びます。
このトピックの内容
概要
索引は、特殊記号、数字、アルファベットの順番で表示するようにソートされます。 初期設定では、句読点はソートでは無視され、アルファベットは英語をソートする順序で表示されます。
索引エントリのソート順序を指定する
ソート順序を指定して、索引のエントリの位置を変更できます。 例えば、「486」というエントリは通常、索引では他の数字と同じ位置に表示されますが、これを「よんひゃくはちじゅうろく」として「や行」のエントリの下に表示できます。 また、サブエントリに「See also」(も参照)という相互参照を使用する場合、これが常にメインエントリの一番下に表示されるように指定することもできます。
マーカーテキストの最後に角かっこ([ ])で括ったテキストを追加して、エントリのソート順序を指定します。
索引マーカーテキスト |
索引の結果 |
説明 |
|---|---|---|
|
Neap tides 47 1950s 10 North America 21 |
N行にソートされます(Nineteen fifties)。 |
|
Erosion rate 32 of soil 10 |
「of」を無視します。 |
「Wind」も参照
|
Erosion 「Wind」も参照 rate 16 |
「Erosion」の最初のエントリとしてソートします。 |
「Wind」も参照
|
Erosion rate 16 「Wind」も参照 |
「Erosion」の下の最後のエントリとしてソートします。 |
索引のソート順序を指定する
ソート順序の変更には、ソート順序を指定し、IX リファレンスページにある IX テキストフローの「IgnoreCharsIX」段落と「SortOrderIX」段落の内容を編集します。
特殊テキストフローにある「SortOrderIX」という段落に、索引内での文字のソート方法を指定する構成要素が指定されています。

ソート順序の各構成要素には、一連の文字が特定の順序で並んでいます。 次の表に、英語版の順序を示します。 アルファベットのソートの順序は、言語によって多少異なります。
構成要素 |
文字とその順序 |
|---|---|
|
0 1 2 3 4 5 6 7 8 9 |
|
A Á À Â Ä Ã Å a á à â ä ã å ª B b C Ç c ç D d E É È Ê Ë e é è ê ë F f ƒ Gg H h I Í Ì Î Ï i ì í î ï J j K k L l M m N Ñ n ñ O Ó Ò Ô Ö Õ Ø o ó ò ô ö õ ø º P p Q q R r S s T t U Ú Ù Û Ü u ú ù û ü V v W w X x Y Ÿ y ÿ Z z |
|
ASCII コードの順序で並ぶその他の文字 |
を選択し、索引用の特殊テキストフローを含むリファレンスページを表示します。
「SortOrderIX」段落の構成要素を、目的のソートの順序に並べた実際の文字で置き換えます。
新しいソート順序を入力する場合は、次の規則に従います。
<$alphabetics>を個別の文字で置き換える場合は、文字グループの間にスペースを 1 つ挿入することで区別します。(文字グループ(例えば、「F f ƒ」など)は、同じ文字としてソートされる文字です(ただし、これらの文字がソートテキスト内で唯一異なる文字である場合は例外です)。 ただし、ソートするテキスト内に 1 つの文字グループしかない場合は、この文字列にある最初の文字が最初に表示されます)。<$symbols>を個別の文字で置き換える場合、山形括弧( < > )の前にはバックスラッシュを使用します。各行の最後で Return キーを押さないでください。 行末の文字を自動的にラップさせます。
2 文字を 1 文字としてソートするように指定する場合は、その 2 文字を山形かっこ(< >)で括り、例えば、「C Ç c ç<CH><Ch><ch>」のように入力します。 この例では、各文字と 2 文字のペアが「C」という 1 つの文字グループに属します。 2 文字の CH は C の文字の後ろに、大文字のペアは小文字のペアの前に並びます。
単語単位ではなく文字単位でソートを行う
単語ごとに索引文字を並べ替えるには、次の手順を実行します。
を選択し、索引用の IX テキストフローを含むリファレンスページを表示します。
IX リファレンスページの IX テキストフローにある IgnoreCharsIX 段落の先頭にスペースを追加します。
文字単位のソート
単語単位のソート
Seabed
Sea level
Seasonal change
Sea walls
Sea level
Sea walls
Seabed
Seasonal change
無視する文字を指定する
索引エントリのソートの初期設定では、ハイフン、非分離ハイフン、en
ダッシュおよび em ダッシュが無視されるように指定されています。
この他に、コンマ、ピリオド、角括弧、中括弧、引用符と感嘆符、通貨記号などの文字を無視するように指定することもできます。
-_–—,.()[]{}$?!"索引の生成時に無視する文字を指定するには、次の手順に従います。
を選択し、索引用の IX テキストフローを含む IX リファレンスページを表示します。
「IgnoreCharsIX」の段落を編集します。
記号や数字やその他の文字を索引内の別の位置にソートする
記号や数字やその他の文字を索引内の別の位置にソートするには、次の手順に従います。
を選択し、索引用の特殊テキストフローを含むリファレンスページを表示します。
特殊テキストフローにある「SortOrderIX」段落の構成要素を並べ替えます。例えば、英語の索引で、記号を最初ではなく最後に表示するには、構成要素を
<$numerics><$alphabetics><$symbols>のように入力します。
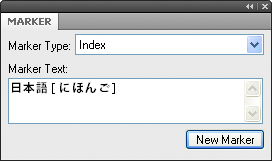
日本語のソート順序を指定する
漢字は常にソート順序を指定する必要があります。
日本語フォントを使用する文書には、日本語の仮名(平仮名とカタカナ)のソート順序を指定する <$kana> という構成要素が含まれます。
構成要素 |
文字とその順序 |
|---|---|
|
 |
半角のカタカナは、ソート時に生成ファイルで全角のカタカナに変換されます。 漢字のソート順序は読み仮名で決まります。
このため、<$kana> 構成要素でほとんどの漢字のソートも制御されます。
読み仮名のない漢字および日本語の記号(全角の数字とローマ字)のソート順序は、初期設定では <$kana> 構成要素に含まれていません。漢字はコード値に基づいてソートされ、<$kana> でソートされた文字の後に続きます。
読み仮名のない漢字と日本語記号のソート方法を変更するには、これらの文字を <$numerics>、<$alphabetics>、<$kana> のいずれかの構成要素に追加します。例えば、全角の日本語文字を <$symbols> 構成要素に追加することができます。
マーカーテキストに、角かっこで括った読み仮名を入力します (ここでは、全角の角かっこも使用できます)。