XPathクエリー
XML文書はエレメントの階層構造で構成されます。XPathクエリーを使用して、XML文書内でエレメントと属性間を移動します。
例えば、次のXML文書内で段落を検索する場合です。
<body>
<p>The quick brown fox.</p>
<p>Jumped over the lazy dogs.</p>
</body>
次のXPathクエリーに対し、XPath検索は2つの結果を返します。
body/p
エレメントの1つに対して属性値を指定している場合:
<body>
<p>The quick brown fox.</p>
<p audience = "admin">Jumped over the lazy dogs.</p>
</body>
検索に属性値を含めます:
body/p[@audience='admin']
XPath検索は1つの結果を返します。
次の表は、XPathクエリーのサンプルのリストです。
|
XPathクエリー |
場所 |
|---|---|
|
/task |
XMLファイルのトップレベルノードである<task>エレメント |
|
//task |
XMLファイルの任意の場所にある<task>エレメント |
|
//task[@id='shovellingsnow'] |
id属性にshovellingsnow値がある<task>エレメント |
|
task/title |
<task>エレメントの直系子孫であるすべての<title>エレメント |
|
task//title |
<task>エレメントの任意の場所で発生するすべての<title>エレメント |
XPathについて詳しくは、http://www.w3.org/TR/xpath/を参照してください
XPathツールバー
1)XPathツールバー(表示/ツールバー/XPath)を開きます。
XPathツールバー

2)XPathフィールドで、クエリーを入力して「実行」をクリックします。
クエリーの結果がXPathビルダーポッドに表示されます。
XPathビルダーポッド
クエリービルダーは、XPathクエリーの作成にも便利なインターフェイスです。クエリビルダーでは、XPathクエリーを作成(自動候補機能を使用)して実行できます。
検索の範囲を指定することもできます。
•現在のファイル
•開いているすべてのファイル
•選択したフォルダー
•DITAマップまたはブック- リソースマネージャーでDITAマップまたはブックを選択すると、このオプションが利用できます。
自動候補
自動候補機能は、クエリーを作成する際にXPathクエリーに追加できるコンポーネント候補を提示します。
例えば、次のXMLで以下の手順を行います。
<body>
<p>The quick brown fox.</p>
<p audience = "admin">Jumped over the lazy dogs.</p>
</body>
1)クエリビルダーフィールドで、フォワードスラッシュ(/)を入力します。
フォワードスラッシュを入力するとすぐに、以下の候補が表示されます。
自動候補
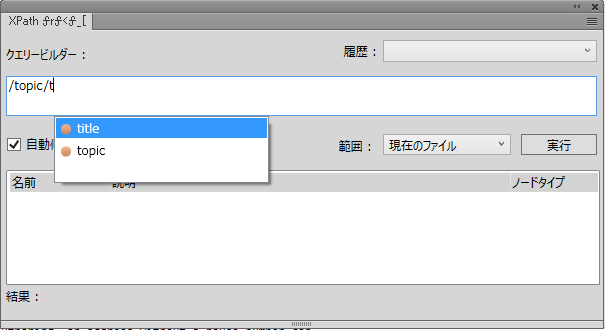
2)上向き矢印および下向き矢印を使用して、オプションを選択し、Enterキーを押してクエリーにコンポーネントを挿入します。
3)他のエレメントをクエリーに追加するには、フォーワードスラッシュを入力します。
また、左角括弧([)を入力してもクエリーに追加できます。
自動候補リストにはXPathクエリーの次のコンポーネントが含まれます。
エレメント(オレンジ色のインジケーター)
現在の文書の現在の位置にあるエレメント。
属性(青色のインジケーター)
現在の文書の現在の位置にある属性。
軸(緑色のインジケーター)
現在のノードに関連するノード定義。例えば、親、子、先祖など。
「自動候補を有効にする」オプションの右にあるドロップダウンリストをクリックして、「軸」オプションの選択を解除し、自動候補リストで利用可能な軸を非表示にします。
注: クエリービルダーの自動候補機能を無効にできます。
保存アイコンをクリックして、XPathクエリーの現在の結果を保存します。